Apache Airflow는 워크플로우를 작성, 예약 및 모니터링하기 쉽게 하는 오픈 소스 워크플로우 관리 시스템입니다.
Airflow는 작업을 자동화하고 예약하며 종속성을 가진 작업을 연결하는 데 사용할 수 있는 워크플로우 오케스트레이터 및 스케줄러입니다. 워크플로우는 시작부터 끝까지의 연산 순서로, Airflow에서는 일반 Python 프로그래밍을 사용하여 Directed Acyclic Graphs (DAG)로 작성됩니다. DAG가 언제 실행을 시작하고 종료해야 하는지 구성할 수 있으며 매우 직관적인 Airflow UI를 통해 워크플로우 모니터링을 설정할 수 있습니다.
Airflow를 쉽게 사용할 수 있으며 기본적인 Python 지식만 필요하므로 빠르게 시작할 수 있습니다. 또한 완전히 오픈 소스입니다. 또한 Apache Airflow에는 Google Cloud, Azure 및 AWS 플랫폼과 쉽게 작동하는 유용한 연산자 모음이 있습니다.

Apache Airflow는 웹-API 기반 플랫폼으로, 스케줄러, 작업 및 관련 워크플로우를 관리하는 데 사용할 수 있는 동반 사용자 웹 인터페이스가 설치됩니다.
일정한 작업 파이프라인을 구축하려는 누구에게나 필수인 도구입니다.
1. Apache Airflow 간단 개요
Apache Airflow는 여러 워크플로우를 만들고 실행할 수 있는 확장 가능한 플랫폼입니다. 워크플로우를 일련의 작업 또는 특정 기능을 수행하는 파이프라인으로 생각할 수 있습니다.
모든 것은 Airflow에서 DAGs(유향 비순환 그래프)를 중심으로 돌아갑니다.
1.1 DAG는 유향 비순환 그래프(DAG)
Apache Airflow 스케줄링의 핵심 구성 요소는 DAG입니다.

간단히 말해 DAG는 Python으로 작성된 구성 파일입니다. 모든 DAG Python 파일은 하나의 폴더에 저장됩니다. 더 나아가, 동일한 DAG의 여러 인스턴스를 병렬로 실행하여 확장성을 제공할 수 있습니다.
DAG는 작업의 컨테이너입니다. 작업(활동)을 정의하고 연결하며 재시도 및 실패 로직을 지정하고 작업 간 데이터 전달 및 데이터 파이프라인을 생성하는 템플릿입니다. DAG 파일은 무거운 프로세스를 수행해서는 안됩니다. 단순히 구성 템플릿일 뿐입니다.
DAG는 데이터 파이프라인을 지정하는 경량 Python 스크립트입니다. DAG가 트리거될 때 DAGRun이 생성됩니다.
각 DAG는 고유한 ID를 가지며 DAG에 참조되는 각 작업에서 DAG 매개변수를 사용할 수 있습니다.
일부 DAG 매개변수의 일부를 보면 아래와 같습니다.
default_args={
'depends_on_past': False,
'email': ['fintechexplained@farhad.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
'queue': 'bash_queue',
'pool': 'backfill',
'priority_weight': 10,
'end_date': datetime(2016, 1, 1),
'wait_for_downstream': False,
'sla': timedelta(hours=2),
'execution_timeout': timedelta(seconds=300),
'on_failure_callback': some_function,
'on_success_callback': some_other_function,
'on_retry_callback': another_function,
'sla_miss_callback': yet_another_function,
'trigger_rule': 'all_success'
}워크플로우는 DAG이며, DAG는 작업의 컨테이너입니다.
1.2 작업
DAG는 여러 작업으로 구성됩니다. 각 작업은 특정 기능을 수행하는 작업 단위입니다. 예를 들어, 작업은 웹 서비스를 쿼리할 수 있고 파일을 생성하거나 기계 학습 모델을 훈련하거나 외부 시스템을 트리거할 수 있습니다. 이러한 작업은 서로 의존 관계를 갖을 수 있습니다.
작업은 특정 순서대로 실행될 수 있으며 재시도될 수 있습니다.
기본적으로 작업은 작업 단위의 Python 함수입니다. 이것은 우리를 연산자(Operators) 개념으로 이끕니다.
1.3 연산자(Operators)
작업은 내장 연산자(템플릿)일 수 있거나 Python에서 사용자 정의 함수를 작성하고 작업(task()) 데코레이터로 장식할 수 있습니다. Airflow는 BashOperator, PythonOperator, EmailOperator 등 다양한 미리 작성된 연산자로 제공됩니다.
작업은 외부 시스템에서 이벤트를 기다리는 센서(Sensor) 유형의 연산자일 수도 있습니다.
- LocalFilesystemToGCSOperator – 로컬에서 GCS 버킷으로 파일을 업로드하는 데 사용합니다.
- PythonOperator – Python 호출 가능 항목을 실행하는 데 사용합니다.
- functionEmailOperator - 이메일을 보내는 데 사용합니다.
- SimpleHTTPOperator - HTTP 요청을 만드는 데 사용합니다.
1.4 스케줄러
Airflow에는 워크플로우를 스케줄링하고 DAG를 모니터링하는 스케줄러가 있습니다. 스케줄러는 DAG의 작업을 제어하고 의존성이 충족되면 작업을 트리거합니다. 스케줄러는 여러 프로세스를 시작할 수 있으며 작업을 실행하고 DAG 폴더와 동기화합니다.
1.5 실행자(Executors)
Sequential Executor, Local Executor 및 Celery Executor와 같은 여러 실행자가 Airflow와 함께 설치됩니다. 실행자는 작업 실행을 제어합니다. Celery Executor는 Airflow 확장을 위해 사용됩니다.
실행자는 작업과 작업자를 여러 개 실행하고 확장할 수 있습니다.
1.6 데이터베이스
Apache Airflow는 예약된 작업의 상태를 보유하는 데이터베이스에서 데이터를 보관합니다. 데이터베이스는 작업을 실행하는 데 필요합니다. 기본적으로 구성된 데이터베이스는 SQLite입니다. 그러나 다른 데이터베이스인 Postgres와 같은 데이터베이스를 사용할 수도 있습니다.
Airflow는 웹 서버에 호스팅되며 상호작용할 수 있는 API와 웹 인터페이스가 제공됩니다.
2. Apache Airflow 설치
먼저 로컬 머신에 Apache Airflow를 설치하는 과정을 시작해봅시다.
- Docker Desktop을 설치하거나 이미 설치된 경우 실행합니다.
- Airflow 디렉토리를 로컬 머신에 저장할 폴더 구조를 만듭니다. 이러한 Airflow 폴더를 원하는 위치에 생성해도 됩니다.
C:/Users/airflow C:/Users/airflow/dags C:/Users/airflow/plugins C:/Users/airflow/logs- 다음과 같은
docker-compose.yml파일을 작성합니다.version: '3' x-airflow-common: &airflow-common image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.0.2} environment: &airflow-common-env AIRFLOW__CORE__EXECUTOR: CeleryExecutor AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0 AIRFLOW__CORE__FERNET_KEY: '' AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true' AIRFLOW__CORE__LOAD_EXAMPLES: 'true' AIRFLOW__API__AUTH_BACKEND: 'airflow.api.auth.backend.basic_auth' volumes: - ./dags:/opt/airflow/dags - ./logs:/opt/airflow/logs - ./plugins:/opt/airflow/plugins user: "${AIRFLOW_UID:-50000}:${AIRFLOW_GID:-50000}" depends_on: redis: condition: service_healthy postgres: condition: service_healthy services: postgres: image: postgres:13 environment: POSTGRES_USER: airflow POSTGRES_PASSWORD: airflow POSTGRES_DB: airflow volumes: - postgres-db-volume:/var/lib/postgresql/data healthcheck: test: ["CMD", "pg_isready", "-U", "airflow"] interval: 5s retries: 5 restart: always redis: image: redis:latest ports: - 6379:6379 healthcheck: test: ["CMD", "redis-cli", "ping"] interval: 5s timeout: 30s retries: 50 restart: always airflow-webserver: <<: *airflow-common command: webserver ports: - 8080:8080 healthcheck: test: ["CMD", "curl", "--fail", "http://localhost:8080/health"] interval: 10s timeout: 10s retries: 5 restart: always airflow-scheduler: <<: *airflow-common command: scheduler restart: always airflow-worker: <<: *airflow-common command: celery worker restart: always airflow-init: <<: *airflow-common command: version environment: <<: *airflow-common-env _AIRFLOW_DB_UPGRADE: 'true' _AIRFLOW_WWW_USER_CREATE: 'true' _AIRFLOW_WWW_USER_USERNAME: ${_AIRFLOW_WWW_USER_USERNAME:-airflow} _AIRFLOW_WWW_USER_PASSWORD: ${_AIRFLOW_WWW_USER_PASSWORD:-airflow} flower: <<: *airflow-common command: celery flower ports: - 5555:5555 healthcheck: test: ["CMD", "curl", "--fail", "http://localhost:5555/"] interval: 10s timeout: 10s retries: 5 restart: always volumes: postgres-db-volume:- Docker 이미지는
apache/airflow:2.0.2입니다. - 이 파일은 환경 변수 및 Postgres 데이터베이스 연결 설정을 저장하는 스크립트를 포함하며 파일용 볼륨을 매핑합니다.
- 웹 서버는 포트 번호 8080에서 호스팅되며 사용자 이름과 암호는 모두
airflow입니다.
- Docker 이미지는
- 명령 줄 또는 PyCharm 터미널을 열고 다음 명령을 실행합니다.
이것은 Docker 컨테이너를 만들고 포트 8080에서 실행합니다.docker-compose up airflow-init docker-compose up - Docker Desktop 애플리케이션을 열면 로컬호스트, 포트 8080에서 실행 중인 Airflow 컨테이너 인스턴스가 표시됩니다.
이로써 Apache Airflow를 성공적으로 설치하고 실행하였습니다.
3. Apache Airflow 사용
- 웹 브라우저를 엽니다. 다음 주소로 이동합니다: http://localhost:8080
- 다음과 같은 정보를 입력합니다.
- 사용자 이름: airflow
- 비밀번호: airflow

- 웹 인터페이스에서 로그, 작업, DAG 실행, 작업, 구성과 같은 관리 작업을 볼 수 있습니다.
- 'DAGs' 메뉴 항목을 클릭합니다.

여기서 기본 DAG, 이전 상태 및 일정을 볼 수 있습니다. 기본적으로 모든 DAG는 비활성화되어 있으므로 DAG가 일시 중지되었습니다. 왼쪽에 있는 토글 버튼을 클릭하여 활성화할 수 있습니다. 또한 웹 페이지에서 Play 버튼을 클릭하여 예약된 작업을 트리거할 수 있습니다.
Airflow는 Swagger 인터페이스와 함께 API도 제공합니다. 다음 주소로 이동합니다: http://localhost:8080/api/v1/ui/

Swagger 인터페이스를 사용하여 Airflow API와 상호작용할 수 있습니다. 이것은 이미 기업 응용 프로그램의 작업을 모니터하고 사용하기 위해 Airflow를 포함시키려는 경우, 기존 애플리케이션이 작업을 수행하도록 Airflow API를 사용하려는 경우 유용합니다.
설정
C:\Users\airflow 폴더로 이동하면 airflow.cfg라는 파일을 볼 수 있습니다. 이 파일은 Apache Airflow 인스턴스의 설정 설정을 저장하는 구성 파일이며 연결 문자열, 암호 등을 포함합니다. 또한 메뉴 항목 'Admin → Configuration'에서 UI를 통해 설정을 액세스할 수 있습니다.
Python으로 첫 Airflow 작업 만들기
이제 Python Airflow DAG를 작성하는 방법을 시작할 준비가 되었습니다.
from airflow import DAG
from datetime import datetime
from airflow.operators.python_operator import PythonOperator
def message():
print("First DAG executed Successfully!!")
with DAG(dag_id="FirstDAG", start_date=datetime(2023,10,18), schedule_interval="@hourly",
catchup=False) as dag:
task = PythonOperator(
task_id="task",
python_callable=message)
task대부분의 사용 사례를 다루는 다섯 가지 예제를 제시하겠습니다. 이 다섯 가지 예제는 여러 작업을 포함하거나 하나의 작업이 여러 작업을 실행할 수 있는 DAG, 작업 간 데이터를 전달할 수 있는 작업, 마지막으로 하나의 DAG가 다른 DAG를 호출하는 방법을 보여줄 것입니다.
Python 예제 1
첫 번째 예제에서는 두 개의 작업을 가진 DAG를 만드는 방법을 보여줍니다. 첫 번째 작업은 두 번째 작업을 성공적으로 실행하도록 호출하는 방법을 보여줍니다. 첫 번째 작업은 내장 PythonOperator를 사용하여 현재 날짜와 시간을 출력하고 Python 함수를 실행합니다. 두 번째 작업은 직접 만들어진 사용자 정의 작업입니다. 웹 서비스를 쿼리하고 결과를 CSV 파일에 저장합니다.
C:/Users/airflow/dags 폴더에 fintechexplained.py 파일을 생성하고 코드를 작성합니다.
import os
from datetime import datetime
import requests
from airflow import DAG
from airflow.decorators import task
import logging
from airflow.operators.python import PythonOperator
with DAG('fintechexplained', description='BlogExampleFinTechExplained',
schedule_interval='0 */2 * * *',
start_date=datetime(2023, 10, 18), catchup=False) as dag:
@task
def custom_get_contents_then_save_task():
data_path = f"/opt/airflow/dags/data{datetime.now()}.csv"
logging.info('Write Dir')
os.makedirs(os.path.dirname(data_path), exist_ok=True)
logging.info(f'File={data_path}')
url = "https://raw.githubusercontent.com/apache/airflow/main/docs/apache-airflow/pipeline_example.csv"
response = requests.request("GET", url)
with open(data_path, "w") as file:
file.write(response.text)
logging.info(f'Data written to File={data_path}')
def print_now():
logging.info('WRITING NOW')
logging.info(datetime.utcnow().isoformat())
logging.info('TIME WRITTEN')
print_time_task = PythonOperator(task_id='print_now', python_callable=print_now, dag=dag)
print_time_task >> custom_get_contents_then_save_task()- 스크립트 로직:
- 'fintechexplained'라는 DAG를 정의합니다.
- 2023년 8월 18일부터 시작하여 매 2분마다 실행됩니다.
- 마지막 라인은 작업 의존성을 구성하는 곳입니다. 여기에서
print_time_task가custom_get_contents_then_save_task를 호출함을 볼 수 있습니다.
이제 DAG를 실행하려면 다음 단계를 수행합니다.
- 브라우저를 열고 http://localhost:8080으로 이동합니다.
- DAG 메뉴 항목을 클릭합니다.
- 'fintechexplained' DAG를 검색하면 첫 번째 DAG가 DAG 목록에 자동으로 표시됩니다.

- 활성화되어 있는지 확인합니다. (활성화되지 않은 경우 왼쪽의 토글 버튼을 클릭)
- Play 버튼을 클릭합니다.
DAGRun이 실행되며 모든 2분마다 두 개의 작업을 실행합니다. DAG가 완료되면 CSV 파일이 생성됩니다.
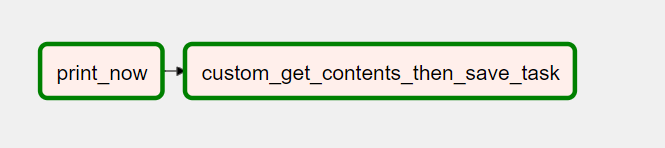
Airflow 웹 인터페이스에서 'fintechexplained' DAG를 클릭한 다음 그래프 보기 메뉴 항목을 클릭하여 작업이 어떻게 연결되었는지 확인할 수 있습니다.
작업 중 하나를 클릭한 다음 로그 옵션을 클릭하여 라이브 로그를 볼 수 있습니다.

또한 DAG 페이지로 돌아가 'fintechexplained' DAG를 클릭한 다음 상세 정보를 보려고 상세 정보 메뉴를 클릭하여 DAG에 관한 모든 필요한 정보를 볼 수 있습니다.
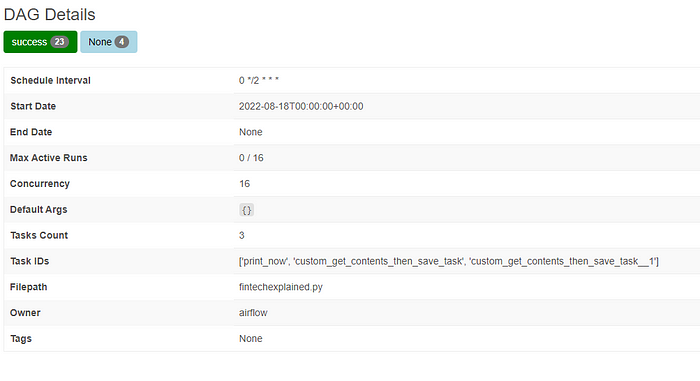
예를 들어 기간, 이전 실행, DAG의 Python 코드 등을 볼 수 있습니다. 또한 예약된 작업을 트리거하고 DAG 관련 기능을 보거나 의존성을 확인할 수 있습니다.
마지막 실행 내역 또한 볼 수 있습니다.
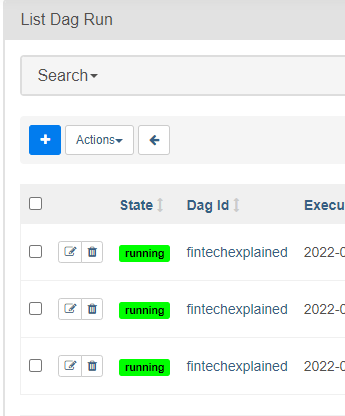
작업 지속 시간을 분석할 수 있습니다.

예제 2: Python을 사용하여 두 개의 작업을 병렬로 실행하기
이 예제에서는 두 개의 작업이 서로 독립적이며 사전 조건이 충족될 때 두 대상 작업을 실행하는 방법을 보여줍니다.
fintechexplained.py파일을 엽니다.- 작업 의존성을 다음과 같이 변경합니다.
print_time_task >> [custom_get_contents_then_save_task(), custom_get_contents_then_save_task()] - 파일을 저장합니다.
- Airflow 웹 인터페이스로 돌아갑니다.
- DAG 메뉴 항목을 클릭합니다.
- 'fintechexplained' DAG를 찾습니다.
- 그래프 보기를 클릭하면 DAG 그래프에 새 작업이 표시됩니다.

여기서 두 작업이 서로 독립적으로 실행되도록 쉽게 구성할 수 있습니다.
Play 버튼을 클릭하여 DAG를 트리거할 수 있습니다.

DAG 실행이 완료되면 DAG가 두 개의 CSV 파일을 생성한 것을 알 수 있습니다. 이는 custom_get_contents_then_save_task 작업이 데이터를 웹 서비스에서 쿼리하고 데이터를 CSV 파일에 저장하기 때문입니다.
예제 3: 여러 작업을 연결하기
데이터 파이프라인을 가능한 한 복잡하게 구축할 수 있습니다. 다른 예제를 살펴보겠습니다. 여기서 여러 작업을 연결하려고 시도합니다. 예를 들어, 여러 기계 학습 모델을 훈련하고 모델이 훈련되면 이메일을 받기를 원할 수 있습니다.
아래 이미지는 시작 작업이 do_first_task를 호출하고 do_first_task가 do_second_task 및 do_third_task_with_second_task를 동시에 호출하는 방법을 보여줍니다. 또한 각 작업은 goodbye_link_to_all 작업을 호출합니다.

DAG를 만든 Python 스니펫입니다.
import os
from datetime import datetime
import requests
from airflow import DAG
from airflow.decorators import task
from airflow.operators.python_operator import PythonOperator
import logging
with DAG('test', description='BlogExampleFinTechExplained',
schedule_interval='0 */2 * * *',
start_date=datetime(2023, 10, 18), catchup=False) as dag:
@task
def start():
pass
@task
def do_first_task():
pass
@task
def do_second_task():
pass
@task
def do_third_task_with_second_task():
pass
@task
def do_forth_task():
pass
@task
def goodbye_link_to_all():
pass
start() >> do_first_task() >> [do_second_task(), do_third_task_with_second_task()]
list(dag.tasks) >> goodbye_link_to_all()
예제 4: 작업 간 데이터 전달하는 방법
다른 예제를 살펴보겠습니다. 여기서 문자열을 생성하고 이를 딕셔너리에 저장합니다. 이 딕셔너리는 후속 작업에 전달됩니다. 예를 들어, 첫 번째 작업은 CSV 파일을 만들고 두 번째 작업에 파일에 대한 작업을 수행하도록 경로를 전달할 수 있습니다.
이 DAG는 passdata라고 불립니다.

DAG를 만든 Python 스니펫 passdata.py 파일 코드입니다.
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
with DAG('passdata', description='BlogExampleFinTechExplained',
schedule_interval='0 */2 * * *',
start_date=datetime(2023, 10, 18), catchup=False) as dag:
@task(task_id='start', retries=2)
def start():
context = {}
my_file_name = 'fintechexplained{date}'.format(date=datetime.now())
context['my_file_name'] = my_file_name
return context
@task
def
main(context):
my_file_name = context['my_file_name']
print(f'main-->{my_file_name}')
return context
@task
def end(context):
my_file_name = context['my_file_name']
print(f'end-->{my_file_name}')
data = start()
result = main(data)
end(result)파일을 저장한 후 메뉴에서 DAG가 표시되며 DAG를 활성화하고 트리거할 수 있습니다.
결과 : 메인 작업 로그
[2023-10-20 22:26:25,591] {logging_mixin.py:104} INFO - main-->fintechexplained2023-10-20 22:26:24.406310결과 : 끝 작업 로그
[2023-10-20 22:26:26,316] {logging_mixin.py:104} INFO - end-->fintechexplained2023-10-20 22:26:24.406310메인 작업이 문자열 변수를 생성하고 끝 작업이 이를 수신한 것을 볼 수 있습니다.
예제 5: 다른 DAG에서 DAG 호출하기
마지막으로, DAG 간에 의존성을 만드는 방법을 보여줄 것입니다. 작업 간에 의존성이 있는 일괄 작업을 실행하려면 유용합니다.
TriggerDagRunOperator를 사용하여 DAG를 트리거합니다. 두 개의 작업이 있습니다.
- 시작 작업이 먼저 실행됩니다.
- 그런 다음 이전에 구현한 'passdata'라는 DAG를 트리거합니다.
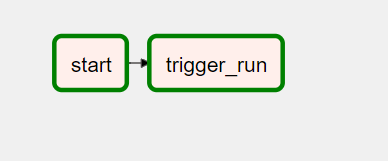
DAG를 만든 Python 스니펫 calldag.py 파일 코드입니다.
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
with DAG('calldag', description='BlogExampleFinTechExplained',
schedule_interval='0 */2 * * *',
start_date=datetime(2023, 10, 18), catchup=False) as dag:
@task
def start():
print('start')
trigger_pass_data = TriggerDagRunOperator(
task_id="trigger_run",
trigger_dag_id="passdata",
dag=dag,
)
start() >> trigger_pass_data작업을 클릭하고 로그 메뉴를 클릭하면 결과를 볼 수 있습니다:
[2023-10-20 22:31:15,256] {taskinstance.py:1192} INFO - Marking task as SUCCESS. dag_id=calldag, task_id=trigger_run, execution_date=20231020T223113, start_date=20231020T223115, end_date=20231020T223115
[2023-10-20 22:31:15,277] {taskinstance.py:1246} INFO - 0 downstream tasks scheduled from follow-on schedule check
[2023-10-20 22:31:15,318] {local_task_job.py:146} INFO - Task exited with return code 0이러한 다섯 가지 예제는 여러 작업이 있는 DAG, 하나의 작업이 여러 작업을 실행할 수 있는 DAG, 작업 간 데이터 전달 작업 및 다른 DAG를 호출하는 방법을 보여주었습니다.
4. 몇 가지 꿀팁과 모범 사례
- 항상 DAG를 구성 또는 템플릿 파일로 다루세요. 여기에 예약된 작업이 구성됩니다. DAG 및 작업은 가벼워야 합니다. 따라서 복잡한 논리를 DAG에 추가하는 것을 피하세요. 무거운 사용자 정의 논리를 그 안에 추가하지 않도록 주의하세요.
- 작업은 독립적이며 다른 기계에서 격리되어 실행될 수 있으므로 모든 기계에서 권한이 올바르게 설정되었는지 확인하세요.
- 작업은 항상 원자적이어야 합니다. 즉, 작업은 트랜잭션이어야 하며 멱등한 결과를 생성해야 합니다. 이것은 주어진 입력에 대해 작업이 트리거된 횟수에 관계없이 각 시도에서 동일하게 작동해야 함을 의미합니다. 따라서 레코드를 삽입하는 대신 레코드를 업서트하려고 시도하지 마세요. 작업이 실패할 경우 Airflow가 자동으로 재시도할 수 있는 이 기능은 작업이 멱등하지 않은 경우 데이터를 손상시킬 수 있으므로 작업이 원자적임을 보장하는 것이 중요합니다.
- 작업을 직접 구현하기 전에 이미 있는 내장 작업 연산자를 사용할 수 있는지 항상 확인하세요.
- DAG 내에서 텐서플로우 또는 판다스와 같은 Python 라이브러리가 필요한 경우 해당 작업 내에서만 가져오세요.
- 작업 내에서
datetime.now()를 사용하는 것을 피하세요. - 연결 세부 정보를 환경 변수로 저장하는 것을 고려하세요.
- 일관된 명명 규칙을 따르려고 노력하고 작업 간에 일관된 방식으로 작업 종속성을 설정하세요.
- DAG 폴더를 버전 관리하세요.
- 작업을 삭제하면 해당 작업의 이력이 삭제되므로 이 점을 유의하세요.
- 코드 에디터에서 DAG를 배포하기 전에 항상 DAG를 테스트하세요.
- 작업 간에 큰 데이터를 교환하지 마세요. 대신 메모리 사용량이 낮은 직렬화 가능한 메시지를 전달하세요. 예를 들어, 작업이 CSV 파일에서 데이터를 읽고 쓰고, 다음 작업에서 이 파일을 로드해야 하는 경우 데이터 대신 후속 작업에 파일 경로를 전달하세요.
- 핵심 Airflow 명령어를 얻으려면
airflow cheat-sheet를 입력하세요.
이러한 팁과 모범 사례는 Apache Airflow를 효과적으로 사용하고 DAG를 보다 신뢰성 있게 관리하는 데 도움이 될 것입니다.
Directed Acyclic Graphs (DAGs) 또는 DAGs는 노드와 엣지로 구성됩니다. DAGs에는 루프가 포함되어서는 안 되며 엣지는 항상 방향이 있어야 합니다. 각 DAG 노드는 작업(task)입니다. 노드의 예로는 GCS(구글 클라우드 스토리지)에서 파일을 다운로드하여 로컬로 저장하거나 Pandas를 사용하여 파일에 비즈니스 로직을 적용하거나 데이터베이스 쿼리를 실행하거나 REST 호출을 하거나 파일을 다시 GCS 버킷에 업로드하는 것 등이 있습니다.
5. Docker Composer 활용
GCP에서 Cloud Composer는 Apache Airflow를 기반으로 한 관리형 서비스로, GCS, BigQuery, Cloud Dataflow 등과 같은 다른 GCP 서비스와 기본적으로 통합되어 있습니다.
Cloud Composer 설치 단계
1. Cloud Composer 환경 생성
- GCP 대시보드에서 "Cloud Composer"를 검색하고 "환경 만들기"를 클릭합니다.
- "환경" 옵션에서 "Composer 1"과 같이 자동 크기 조정이 필요하지 않는 옵션을 선택합니다.
2. 기본 구성 설정
- "인스턴스 이름", "위치" 등을 설정합니다. 이때 노드 수는 항상 3으로 설정해야 합니다. GCP는 Airflow에 필요한 3개의 서비스를 설정합니다.
3. Airflow DAG 폴더 열기
- Cloud Composer 환경이 설정되면 "DAGs 폴더"를 열어서 여기에 DAG 파일을 업로드할 수 있습니다.
4. DAG 업로드 및 실행
- 필요한 DAG를 작성한 후 "DAGs 폴더"에 업로드합니다.
- DAG를 실행하려면 Airflow UI를 사용할 수 있습니다. Airflow UI는 "Airflow" 링크를 통해 열 수 있습니다.
파이프라인 작성 및 실행 단계
1. 파이프라인 버킷 설정
- 입력 및 변환 후 파일을 저장할 두 개의 버킷(input_csv 및 transformed_csv)을 설정합니다.
2. 파이프라인 코드 작성
- 파이프라인의 전체 코드를 작성합니다. 다음은 코드 예시입니다.
from airflow import DAG
from datetime import datetime
import pandas as pd
from airflow.utils.email import send_email
from airflow.operators.python_operator import PythonOperator
from airflow.operators.email_operator import EmailOperator
from airflow.providers.google.cloud.transfers.gcs_to_gcs import GCSToGCSOperator
def transformation():
trainDetailsDF = pd.read_csv('gs://input_csv/Event_File_03_16_2022.csv')
print(trainDetailsDF.head())
with DAG(
dag_id="pipeline_demo",
schedule_interval="@hourly",
start_date=datetime(2022, 1, 23),
catchup=False
) as dag:
buisness_logic_task = PythonOperator(
task_id='ApplyBusinessLogic',
python_callable=transformation,
dag=dag)
upload_task = GCSToGCSOperator(
task_id='upload_task',
source_bucket='input_csv',
destination_bucket='transformed_csv',
source_object='Event_File_03_16_2022.csv',
move_object=True,
dag=dag
)
email_task = EmailOperator(
task_id="SendStatusEmail",
depends_on_past=True,
to='youremail',
subject='Pipeline Status!',
html_content='<p>Hi Everyone, Process completed Successfully! <p>',
dag=dag)
buisness_logic_task >> upload_task >> email_task3. DAG 실행 및 모니터링
- DAG를 업로드하고 실행합니다. 성공적으로 실행된 경우 Airflow UI에서 결과를 모니터링할 수 있습니다.
4. 실패 시 이메일 알림 설정 (옵션)
- 작업이 실패한 경우 이메일 알림을 보내려면 on_failure_callback을 설정합니다.
5. 환경 정리 (중요)
- Cloud Composer 사용이 끝나면 Cloud Composer 인스턴스를 삭제하세요. Cloud Composer 인스턴스는 중지할 수 없으므로 필요하지 않을 때는 삭제하는 것이 중요합니다.
단계별로 Cloud Composer를 설치하고 파이프라인을 생성하고 실행하는 방법을 참고하여 GCP에서 Apache Airflow 및 Cloud Composer를 활용할 수 있습니다.




댓글