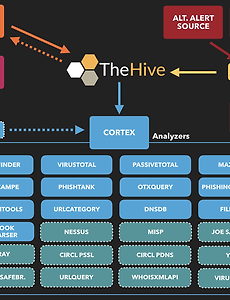
Elasticsearch15 네트워크 패킷 실시간 수집분석 효율적인 중복제거 및 특이사항 필터링 네트워크 패킷을 syslog를 통해 수집할 때, 데이터의 양이 많아 중복 항목을 효율적으로 제거하는 방법(Network Packet Deduplication Strategies)은 여러 가지가 있습니다. 중복 데이터를 제거하는 것은 저장 공간을 절약하고, 분석을 더 빠르고 정확하게 만들어줍니다.해시 함수 사용: 각 패킷에 대한 해시 값을 계산하고, 이 값을 기반으로 중복을 확인합니다. SHA-256 또는 MD5와 같은 해시 함수를 사용하여 각 패킷의 고유한 지문을 생성할 수 있습니다. 이 방법은 데이터의 무결성 검사에도 유용합니다.데이터 정규화: 데이터를 분석하기 전에, 가능한 한 모든 패킷을 표준 형식으로 정규화합니다. 이것은 IP 주소, 타임스탬프 등의 필드에서 발생할 수 있는 미세한 차이를 제거하여.. 2024. 5. 15. Elasticsearch 클러스터 다중 Kibana 인스턴스 연결 구성 하나의 Elasticsearch 클러스터에 여러 Kibana 인스턴스를 연결할 수 있습니다. 이 구성은 대규모 환경이나 다중 조직 환경에서 유용할 수 있습니다. 각 Kibana 인스턴스는 동일한 Elasticsearch 데이터에 대한 접근을 제공하면서도 사용자별, 팀별, 또는 프로젝트별로 맞춤화된 대시보드와 시각화를 제공할 수 있습니다. 다만, 여러 Kibana 인스턴스를 운영할 때 고려해야 할 몇 가지 사항이 있습니다.리소스와 성능: 각 Kibana 인스턴스는 자체적인 서버 리소스를 사용합니다. 따라서, 여러 인스턴스를 운영할 경우 적절한 하드웨어 및 네트워크 리소스를 확보해야 합니다.버전 호환성: 모든 Kibana 인스턴스가 연결되는 Elasticsearch 클러스터와 호환되는 버전이어야 합니다. E.. 2024. 5. 12. Mermaid: 쉬운 다이어그램과 차트 작성을 위한 도구 Mermaid은 JavaScript를 기반으로 한 다이어그램 및 차트 도구입니다. 이 도구는 Markdown 형식의 텍스트를 사용하여 복잡한 다이어그램을 만들고 수정할 수 있는 렌더러를 제공합니다. Mermaid의 주요 목적은 소프트웨어 개발 과정에서 문서 작성을 돕는 것입니다. 보통, 소프트웨어 개발 과정에서는 문서화 작업이 중요하지만, 이 작업은 시간이 많이 소요되고 빠르게 오래되는 경향이 있습니다. 그러나 문서화가 되지 않으면 생산성이 떨어지고, 팀 내 지식 공유와 학습에도 문제가 발생할 수 있습니다. 이런 문제를 해결하기 위해 Mermaid는 사용자들이 쉽게 수정 가능한 다이어그램을 만들 수 있도록 돕습니다. 또한 이를 프로덕션 스크립트나 다른 코드에 통합할 수 있습니다. Mermaid를 사용하면.. 2024. 4. 19. 보안 이벤트 통합 및 보안 사고 대응 플랫폼 TheHive 구성 TheHive는 오픈 소스 보안 사고 대응 플랫폼으로, 이벤트를 통합하고 조직화하여 보안 팀이 보다 효과적으로 대응할 수 있도록 도와줍니다. 리눅스 시스템에서 보안 이벤트를 TheHive로 수집하는 데에는 몇 가지 단계가 포함됩니다. 이를 위해 Elasticsearch와 같은 백엔드 저장소도 사용될 수 있습니다. 아래는 이 과정을 자세히 설명한 것입니다. TheHive 설치 및 설정 TheHive를 설치하고 구성합니다. TheHive는 자체적으로 또는 Docker를 사용하여 설치할 수 있습니다. 필요한 패키지와 구성 파일을 설치하고 설정합니다. Cortex 설치 (옵션) Cortex는 TheHive와 통합되어 자동화된 보안 작업을 지원합니다. Cortex를 설치하고 구성하여 TheHive와의 통합을 활성.. 2024. 2. 8. Elasticsearch Bulk 통한 indexing 중 Limit of total fields 오류 해결 elasticsearch7.helpers.errors.BulkIndexError: ('26 document(s) failed to index.', 이하생략 이 오류는 Elasticsearch에 문서를 색인하려고 할 때 발생한 문제로, 총 필드 수 제한을 초과했다는 것을 나타냅니다. 에러 메시지에서 "Limit of total fields [10000] has been exceeded while adding new fields [2]"라고 나와 있습니다. Elasticsearch에서는 기본적으로 한 인덱스 내 전체 필드 수를 10000개로 제한하고 있으며, 현재 추가하려는 문서에서는 2개의 새로운 필드를 추가하려다가 이 제한을 초과하게 되었습니다. 이 문제를 해결하기 위해서는 몇 가지 방법이 있습니다. 필.. 2024. 1. 30. 이전 1 2 3 다음