프로메테우스를 사용하여 MinIO 클러스터, 노드 및 버킷의 모니터링 및 경고 설정입니다.
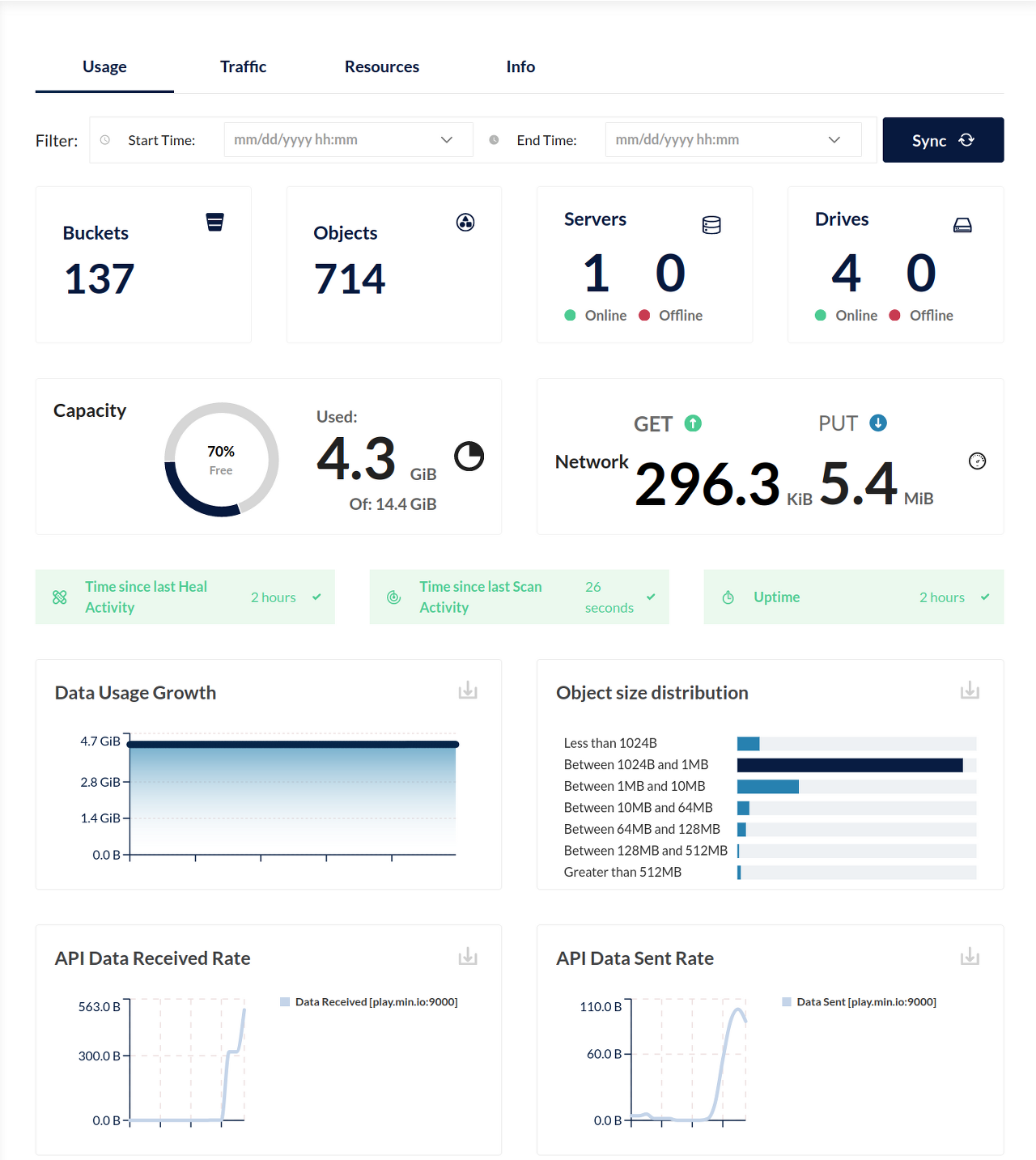
MinIO가 프로메테우스 데이터 모델을 사용하여 MinIO 클러스터, 노드 및 버킷 메트릭을 게시하고 이러한 메트릭을 수집하고 경고를 설정하는 방법에 대해 설명합니다.
다음 세 가지 주요 단계로 나누어져 있습니다.
1. 프로메테우스 수집 구성 생성
- MinIO 서버, 노드 및 버킷 메트릭을 스크레이핑할 프로메테우스 수집 구성을 생성합니다.
- MinIO 서버 메트릭 수집 구성
- MinIO 클러스터의 메트릭을 수집하기 위해 다음 명령을 사용합니다.
mc admin prometheus generate ALIAS명령을 사용하여 MinIO 클러스터의 메트릭을 스크레이핑할 수 있습니다. 여기서 ALIAS를 MinIO 배포의 별칭으로 바꿉니다.
- MinIO 노드 및 버킷 메트릭 수집 구성
- MinIO 노드와 버킷 메트릭을 수집하려면 MinIO 배포에 대한 스크레이핑 구성을 생성합니다.
- 구성 예제
scrape_configs: - job_name: minio-job bearer_token: TOKEN metrics_path: /minio/v2/metrics/cluster scheme: https static_configs: - targets: [minio.example.net] job_name은 MinIO 배포와 관련된 값을 설정합니다. 이 값은 다른 프로메테우스 서비스에서 수집하는 메트릭과 격리하기 위해 고유해야 합니다.MINIO_PROMETHEUS_AUTH_TYPE이 "public"으로 설정된 MinIO 배포에서는bearer_token필드를 생략할 수 있습니다.scheme은 MinIO 배포가 TLS를 사용하지 않는 경우 "http"로 설정합니다.targets배열에는 MinIO 배포를 해결할 수 있는 호스트 이름을 설정합니다. 이 호스트는 단일 노드일 수도 있고 MinIO 노드에 연결을 처리하는 로드 밸런서 또는 프록시일 수도 있습니다.
2. 업데이트된 구성으로 프로메테우스 재시작
- 프로메테우스 구성 파일에 이전 단계에서 생성한 스크레이핑 구성을 추가하고 프로메테우스를 다시 시작합니다.
- 클러스터 메트릭 수집 구성 예제
global:
scrape_interval: 15s
scrape_configs:
- job_name: minio-job
bearer_token: TOKEN
metrics_path: /minio/v2/metrics/cluster
scheme: https
static_configs:
- targets: [minio.example.net]- 버킷 메트릭 수집 구성 예제
prometheus --config.file=prometheus.yaml
3. 수집된 메트릭 분석
- 프로메테우스에는 메트릭을 분석하기 위한 표현식 브라우저가 포함되어 있습니다. 이를 사용하여 수집된 MinIO 메트릭에 대한 쿼리를 실행할 수 있습니다.
- 예제 쿼리
# 클러스터 노드 온라인 및 오프라인 메트릭 조회
minio_cluster_disk_online_total{job="minio-job"}[5m]
minio_cluster_disk_offline_total{job="minio-job"}[5m]
# 버킷 사용량 메트릭 조회
minio_bucket_usage_object_total{job="minio-job"}[5m]
# 클러스터 사용 가능한 여유 바이트 메트릭 조회
minio_cluster_capacity_usable_free_bytes{job="minio-job"}[5m]
4. MinIO 메트릭을 사용한 경고 규칙 구성
- 수집된 MinIO 메트릭을 기반으로 경고를 트리거하기 위해 프로메테우스 배포에서 경고 규칙을 설정합니다.
- 경고 규칙 예제
groups:
- name: minio-alerts
rules:
- alert: NodesOffline
expr: avg_over_time(minio_cluster_nodes_offline_total{job="minio-job"}[5m]) > 0
for: 10m
labels:
severity: warn
annotations:
summary: "MinIO 배포에서 노드 다운"
description: "클러스터 {{ $labels.instance }}의 노드가 5분 이상 오프라인 상태입니다."
- alert: DisksOffline
expr: avg_over_time(minio_cluster_disk_offline_total{job="minio-job"}[5m]) > 0
for: 10m
labels:
severity: warn
annotations:
summary: "MinIO 배포에서 디스크 다운"
description: "클러스터 {{ $labels.instance }}의 디스크가 5분 이상 오프라인 상태입니다."- 경고 규칙 파일을 프로메테우스 구성에 지정합니다.
global:
scrape_interval: 5s
rule_files:
- minio-alerting.yml- 경고가 트리거되면 프로메테우스는 구성된 AlertManager 서비스로 경고를 전송합니다. 이 경고는 필요한 조치를 취할 수 있도록 설정된 AlertManager로 라우팅됩니다.
이제 MinIO 클러스터, 노드 및 버킷에 대한 모니터링 및 경고 설정이 완료되었습니다. 이제 프로메테우스를 사용하여 MinIO의 상태 및 성능을 지속적으로 모니터링하고 필요한 경우 경고를 받을 수 있습니다.
참고 : https://min.io/docs/minio/linux/operations/monitoring/collect-minio-metrics-using-prometheus.html
728x90




댓글